Sprinting a marathon: scaling vulnerability management
If your patching teams are reporting that they’re exhausted, they’ve got good reason. If you haven’t already, it’s time to invest in automation – regression testing and continuous deployment – to help them cope.
NIST publishes the National Vulnerability Database, which provides a pretty good index of all known vulnerabilities. It counts vulnerabilities, each identified by a Common Vulnerabilities Enumeration (CVE) number.
Over the last six months, NVD has recorded about 2,000 new vulnerabilities per month, including about 250 critical1 vulnerabilities per month (remote code execution, which might mean emergency patching). That’s about 12 new critical vulnerabilities per week day and about 90 less-serious vulnerabilities. That’s a pretty high workload for a triage team, much less the patching teams.
| Month | Critical CVEs | Total CVEs |
|---|---|---|
| 2021-08 | 252 | 2236 |
| 2021-09 | 219 | 1917 |
| 2021-10 | 202 | 1708 |
| 2021-11 | 219 | 1610 |
| 2021-12 | 343 | 2400 |
That’s already not great, but the problem is intensifying. Here’s a graph2 of critical and total vulnerabilities published per year.
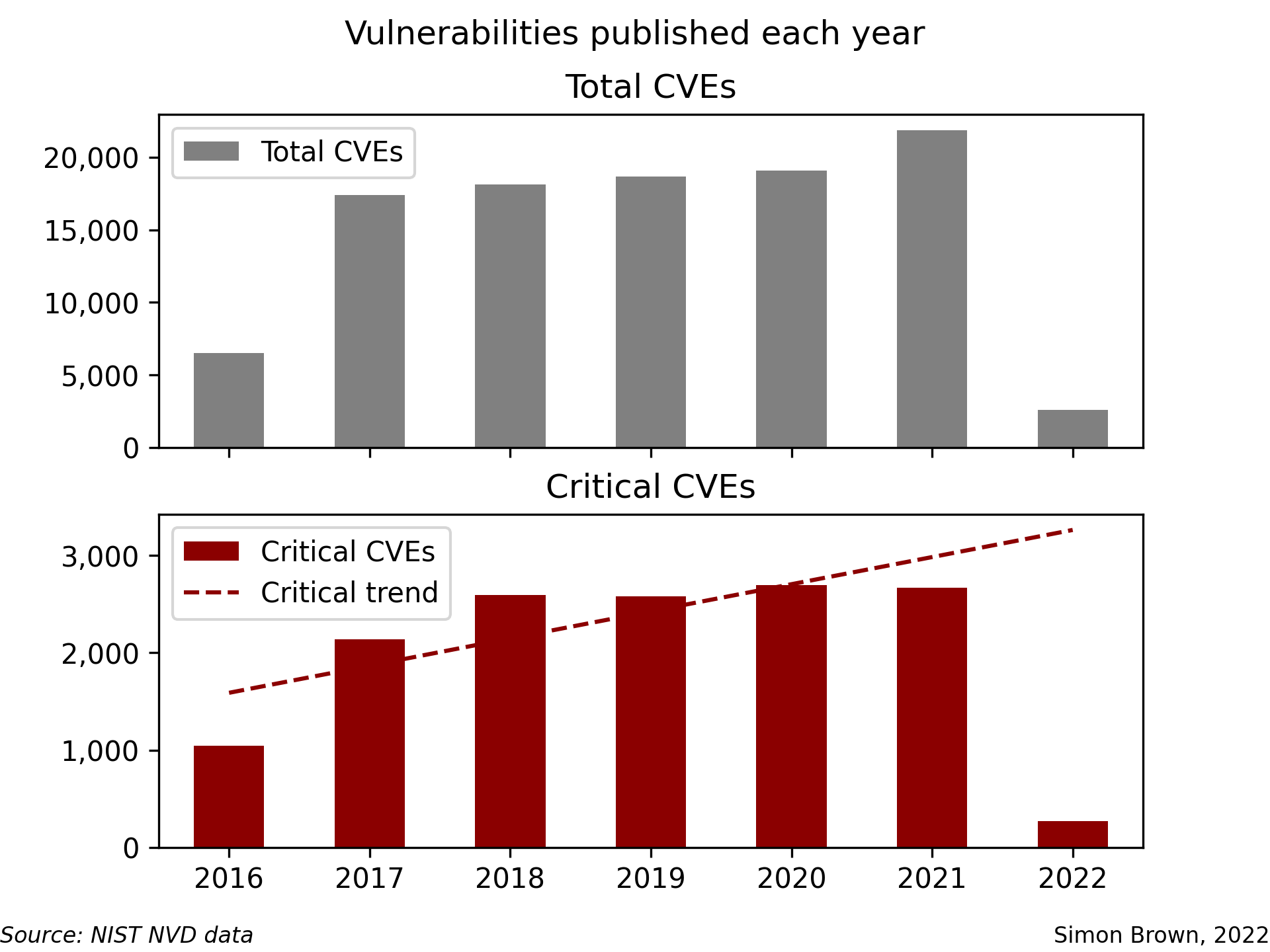 Source: NIST NVD Data; our analysis
Source: NIST NVD Data; our analysis
The trend line on critical vulnerabilities suggests this is going to get worse. Treat it as approximate3, but it suggests that you should expect the number of critical vulnerabilities per year to increase by about ~250 per year. In 2022, we should expect nearly 3,000 critical vulnerabilities to be released.
So, how do you deal with this kind of volume?
Problem one: discovering that you’ve got something that needs patching
There are three useful capabilities here, in decreasing utility (and usefully decreasing cost):
- A comprehensive inventory;
- Vulnerability management (scanning) systems; and
- Monitoring for advisories.
The ideal primary control is a comprehensive inventory of your estate. You could then check a daily extract of the NVD against that inventory, and create work tickets for every team that owns a newly-vulnerable component. In an ideal world, your CMDB is even automating this for you. That said, there’s pretty good chance that practitioners will have either scoffed or grumbled when I said “comprehensive inventory”; I’m not aware of an organisation that thinks it has solved this.
Given that nobody fully trusts their inventory, many organisations augment it with scanning. Typically, this is implemented with a vulnerability management system. Network-based VMS are common, but these can struggle with reachability and completeness (particularly if scans aren’t authenticated). With the increasing frequency and severity of library-level issues, it’s also worth augmenting your network VMS with something that’s keeping an eye on vulnerable libraries; one open source option is Anchore’s grype, which can scan container images and file systems.
The third layer of detection is inexpensive but narrow: relying on your vendors telling you, whether that’s through predictable schedules (e.g., Microsoft Patch Tuesday) or mailing lists. That’s probably best thought of as only being for your most critical and/or widely deployed software, given that it’s unstructured data and difficult to scale.
That said, those answers aren’t particularly satisfying. Hopefully, the state of the art in both automated inventories and vulnerability management will continue to improve completeness and granularity.
Problem two: patching it
Once you know you’ve got something to patch, the hard work begins.
Patching teams typically struggle with the volume of required patching because patching processes are traditionally manual and involve a lot of analysis. A typical process might look like:
- Triage team says a patch is available.
- Analyse patch and perform criticality analysis. (“Do we need to patch this? How quickly?”)
- Deploy patch to development/test environment.
- Perform manual regression testing in dev/test environment.
- Review regression test results; plan for production release.
- Deploy patch to production environments.
- Perform manual regression testing in production environment.
- Monitor for performance impacts.
We can make life easier for ourselves if we make two changes – one cultural, one technical.
The cultural change sounds simple: don’t decide per patch, just patch everything, continuously. If we deploy every available patch, every month, we might have more patching failures but that is offset by freeing up significant time by no longer performing analysis. As a bonus, it also becomes much easier to stay in a supported state.
The technical change requires some capex: automate regression testing and deployment. If you reduce the friction of patch deployment (and roll-backs when necessary), your ability to patch everything continuously dramatically improves.
Those two go together: if you don’t have great regression testing, automatically patching can increase your software supply chain risks.
But where you can implement these two changes, the reward is a much simpler process:
- Detect that patch is available (triage controls above).
- Automated deployment of new version to development/test environment.
- Automated regression test passes (or blocks the pipeline and generates an alarm).
- Automated deployment of new version to production environments.
- Monitor for performance impacts.
You’re down to two manual processes – kicking off the process, and handling any exceptions.
Migrating legacy applications to pipelines can be an expensive one-off change, but given the increasing number of vulnerabilities every year, it’s worth considering.
My thanks to Cole for providing feedback which helped improve this post.
-
In those numbers, we have counted vulnerability as “critical” if it has a CVSSv3 severity of
CRITICAL; or a CVSSv2 base score of 10 if the record has no CVSSv3 score. Typically, those are remote code execution vulnerabilities – the patches you need to get implemented right now, to stop a system compromise. ↩ -
The code to generate the graphs is here, if you’d like to tinker with it. ↩
-
The linear regression has an R² value of only about 0.81. ↩